Researcher in Computer Vision for Sports Analytics.
Ph.D. student specializing in Video Understanding,
Multimodal Learning, and AI-driven Analytics.


ClimbAI – Your AI Climbing Coach
ClimbAI analyzes your climbing videos and delivers clear, actionable feedback on your technique, strengths, and weaknesses. Built by climbers and trained on 6000+ hours of annotated footage across 98 climbers (V0-V12) by 5 certified coaches, our custom VLM is backed by peer-reviewed Computer Vision research. Upload your climb, get expert-level insights, and level up.
PATS: Proficiency-Aware Temporal Sampling for Multi-View Sports Skill Assessment
PATS (Proficiency-Aware Temporal Sampling) is a novel video sampling strategy designed specifically for automated sports skill assessment. Unlike traditional methods that randomly sample frames or use uniform intervals, PATS preserves complete fundamental movements within continuous temporal segments, maintaining the temporal coherence essential for accurate proficiency evaluation.
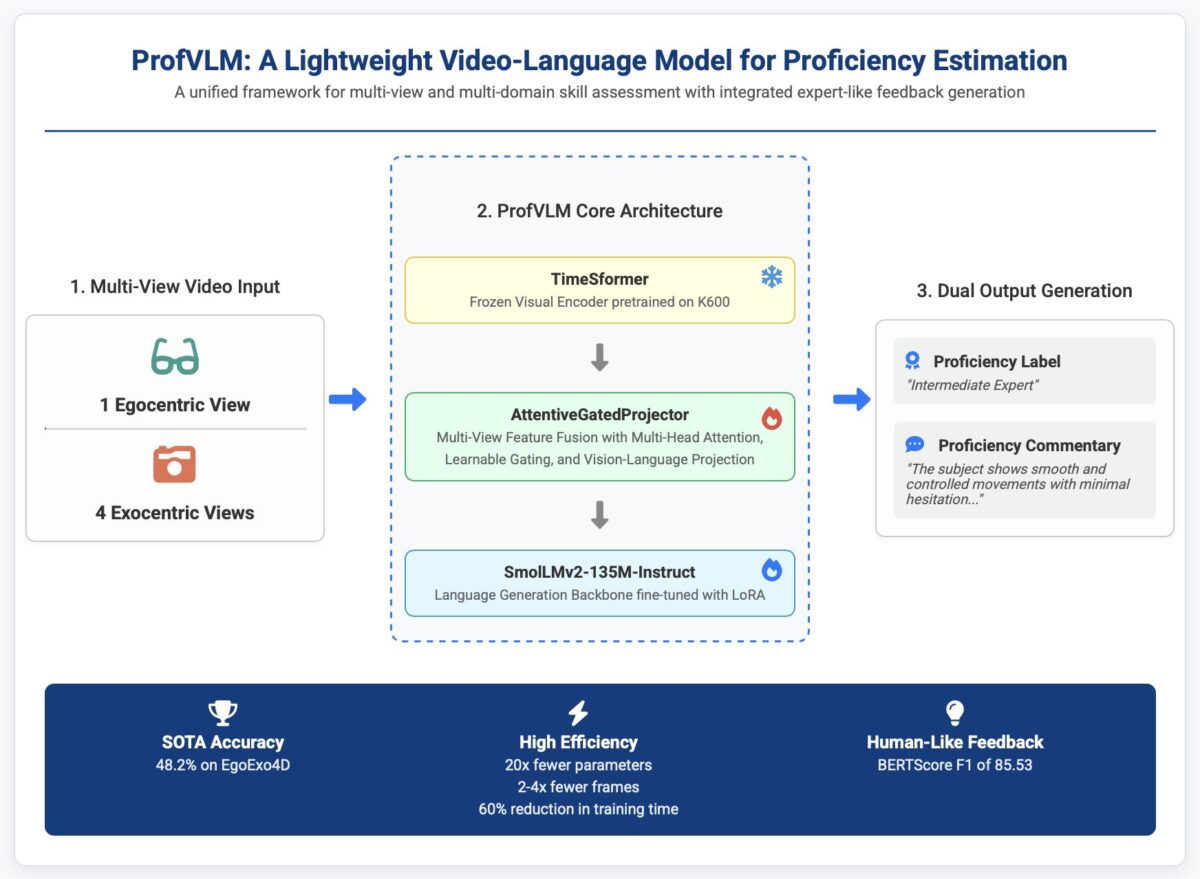
ProfVLM: A Lightweight Video-Language Model for Multi-View Proficiency Estimation
ProfVLM is a lightweight multimodal Vision-Language Model designed to analyze sports performance videos and generate textual proficiency feedback. The system leverages a frozen TimeSformer video encoder and a LoRA-injected SmolLMv2 language model to efficiently process video-text pairs. Trained on EgoExo4D with expert commentaries, ProfVLM surpasses state-of-the-art methods while using up to 20x fewer parameters and reducing training time by up to 60%.
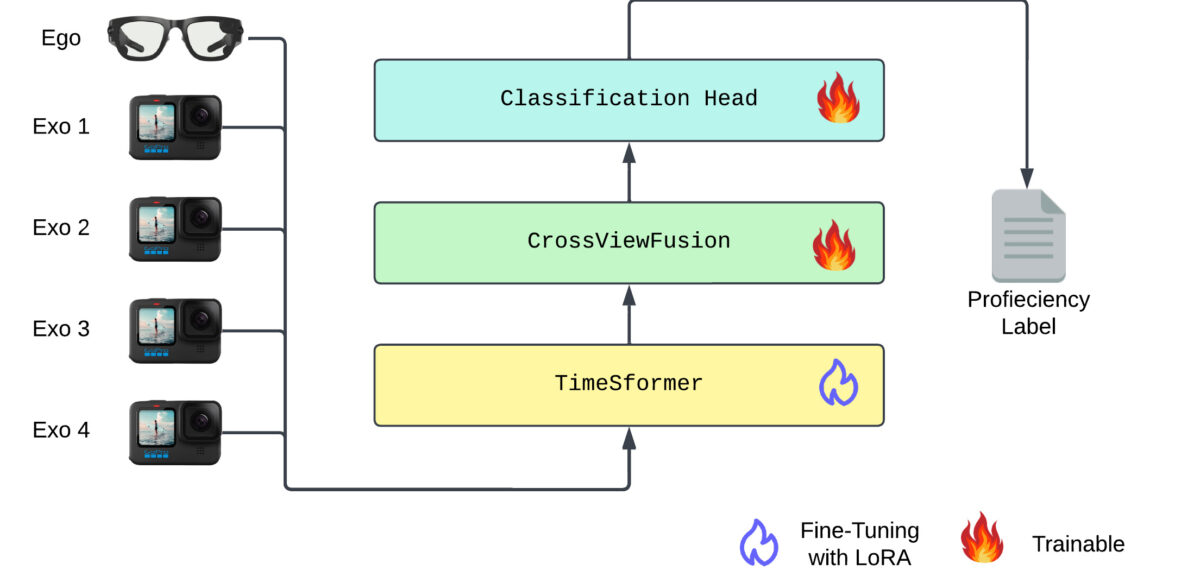
SkillFormer: Unified Multi-View Video Understanding for Proficiency Estimation
SkillFormer is a parameter-efficient transformer for unified multi-view proficiency estimation. Leveraging the TimeSformer backbone enhanced with our novel CrossViewFusion module, it fuses egocentric and exocentric video features using multi-head cross-attention and adaptive gating. Through Low-Rank Adaptation (LoRA), SkillFormer achieves SOTA performance on EgoExo4D while training with 4.5× fewer parameters and 3.75× fewer epochs—making robust skill assessment accessible for real-world deployment.

Gate-Shift-Pose: Enhancing Action Recognition in Sports with Skeleton Information
Gate-Shift-Pose (GSP) is a multimodal architecture designed to enhance action recognition in sports by integrating skeleton-based pose information with RGB frames. The model builds on the Gate-Shift-Fuse (GSF) network and introduces early- and late-fusion strategies to better capture the intricate motion dynamics of sports.

LangChain for LLM Application Development

Building Systems with the ChatGPT API

Azure AI Fundamentals



